EDA e comparação com mercado estrangeiro: 💼
Enquanto construia uma EDA do levantamento feito pelo pessoal do Data Hackers acabei me deparando com essa pequisa feita por Roger Magoulas and Steve Swoyer o que me levou a algumas informações semelhantes ao dados levantos pelo pessoa da DH, logo pensei em montar um notebook pra compartilhar com vocês. É válido ressaltar que os formulários tem objetivos diferentes, o estrangeiro focado em IA e o do pessoal do DH focado em Data Science, porém, alguns informações são pertinentes para comparação.
Tamanho das amostras:
Survey AI Adoption in the Enterprise 2020: 1.388
Data Hackers pesquisa: 1.765
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import json
import folium
from folium import plugins
from statistics import *
from IPython.display import Image
data = pd.read_csv("../input/pesquisa-data-hackers-2019/\datahackers-survey-2019-anonymous-responses.csv", sep=",")
data.head(3)Uma visualização de dados nulos:
fig, ax = plt.subplots(1,1, figsize=(20,5))
sns.heatmap(data.isnull())
data_p = data.groupby(["('D4', 'anonymized_market_sector')"]).size().reset_index()
data_p.columns = ["area", "qtd"]
data_p["qtd_p"] = round((data_p["qtd"]*100)/data_p["qtd"].sum(),2)
data_p.sort_values("qtd_p", ascending=True, inplace=True)
fig = px.bar(data_p, y="area", x="qtd_p", orientation='h', text='qtd_p', title= "DH Survey - Areas de atuação")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.show()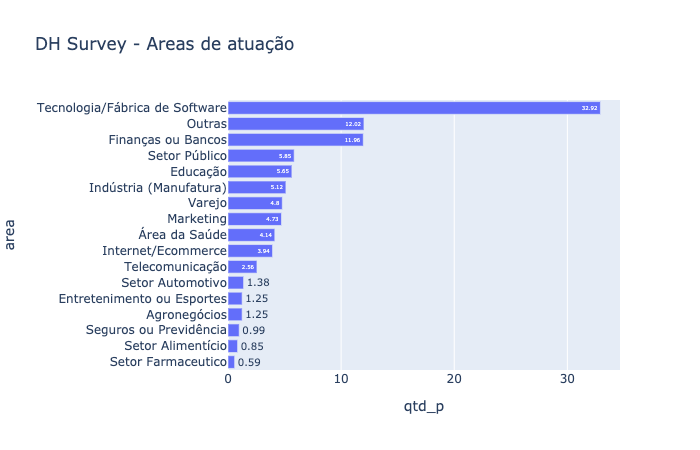
Comparativo com mercado estrageiro:
#atuação de mercado
Image("../input/screenshots/shc1.png")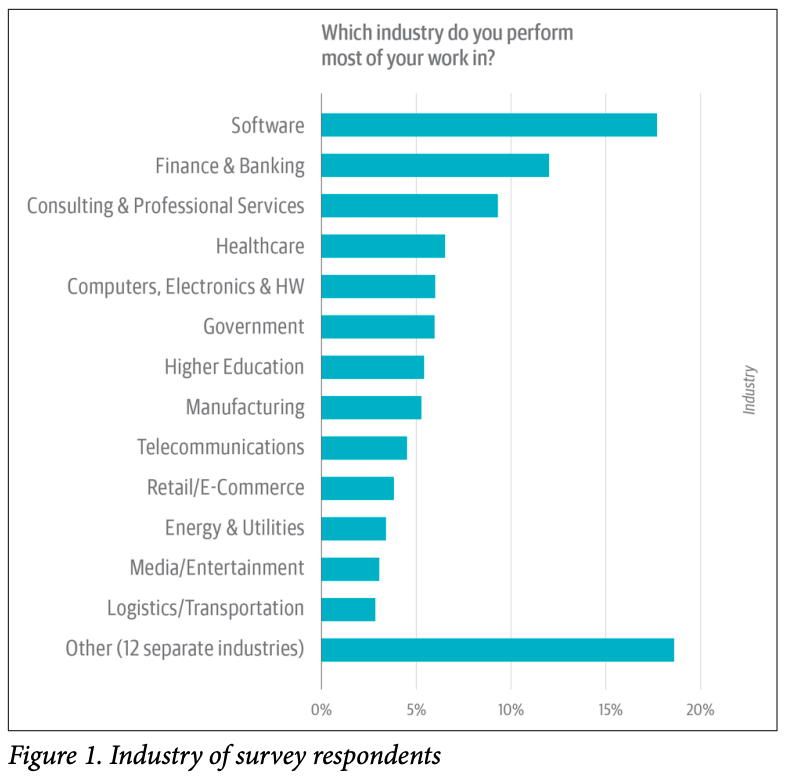
grad_sit = data.groupby(["('D6', 'anonymized_role')"]).size().reset_index()
grad_sit.columns = ["Função", "qtd"]
grad_sit["qtd_p"] = round((grad_sit["qtd"]*100)/grad_sit["qtd"].sum(),2)
grad_sit.sort_values("qtd_p", ascending=True, inplace=True)
fig = px.bar(grad_sit, y="Função", x="qtd_p", orientation='h', text='qtd_p', title="DH Survey - Levantamento de Cargos/Função")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.update_layout(hovermode="x")
fig.show()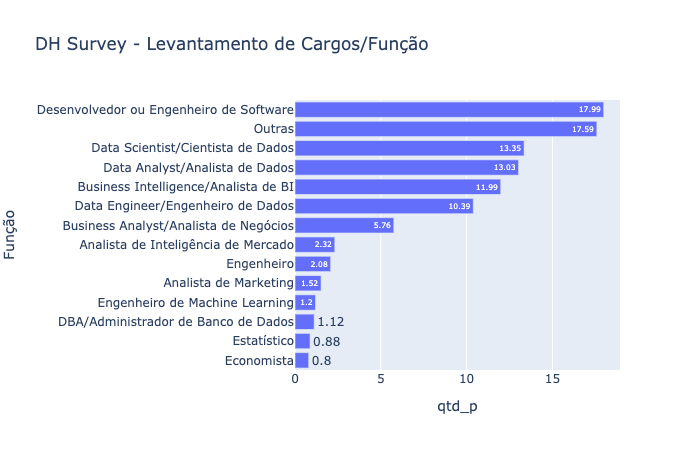
Comparação com mercado estrangeiro:
#atuação de mercado
Image("../input/screenshot2/sch2.png")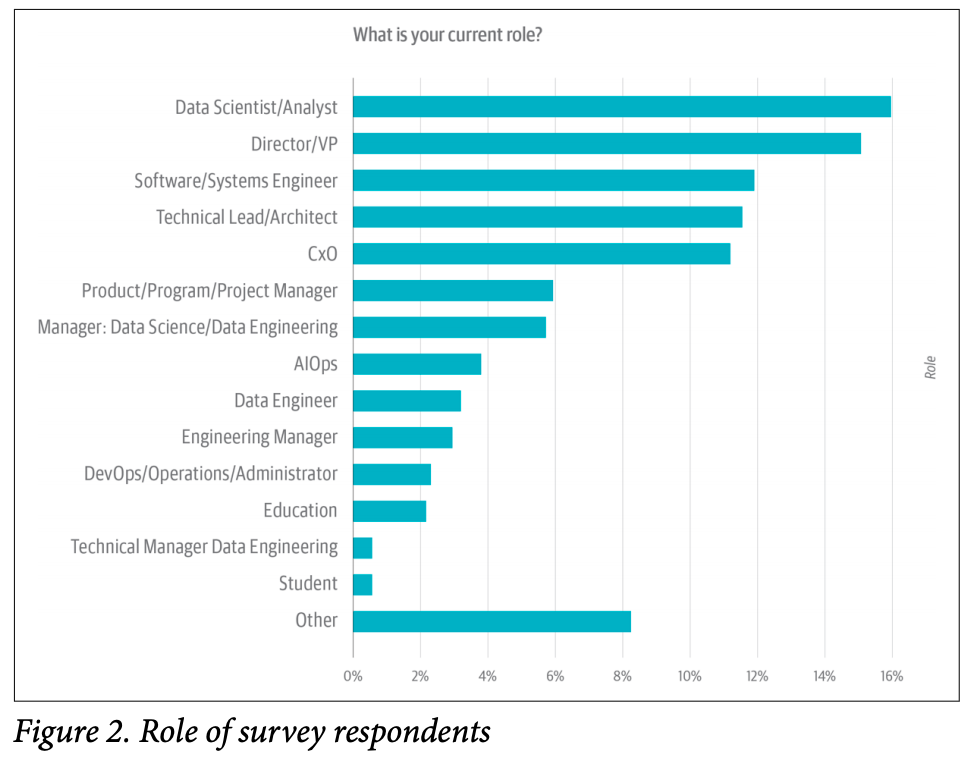
As informações a seguir são um levantamento do survey da DH!
data_p = data.groupby(["('P3', 'living_in_brasil')", "('D3', 'anonymized_degree_area')"]).size().reset_index()
data_p.columns = ["regiao", "area", "qtd"]
data_p = data_p.replace({"regiao": {0:"Exterior", 1:"Brasil"}})
fig = px.bar(data_p, y="regiao", x="qtd", color='area', orientation='h', text='qtd', title= "Quem participou do estudo?")
fig.show()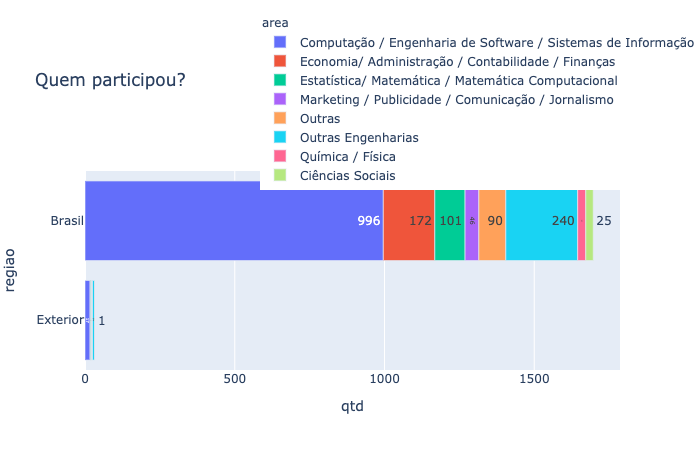
data.loc[(data["('P2', 'gender')"].isnull()), "('P2', 'gender')"] = 'Não informado'
data["('P1', 'age')"] = data["('P1', 'age')"].astype('category')
data["('P2', 'gender')"] = data["('P2', 'gender')"].astype('category')
data.fillna({('P2', 'gender'):"Não informado"}, inplace=True)
fig = px.histogram(data, x="('P1', 'age')", color="('P2', 'gender')", title="Distribuição de idade e gênero dos participantes")
fig.update_layout(hovermode="x")
fig.show()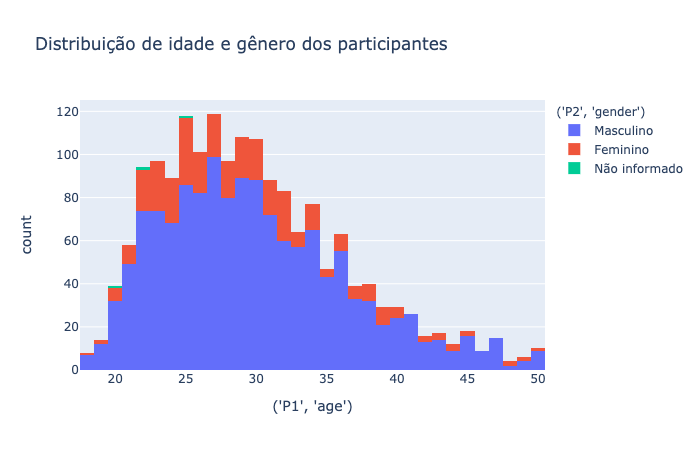
fig = px.box(data, x="('P2', 'gender')", y="('P1', 'age')", title="Distribuição de Gênero e idade", boxmode="overlay", color="('P2', 'gender')")
fig.update_layout(hovermode="x")
fig.show()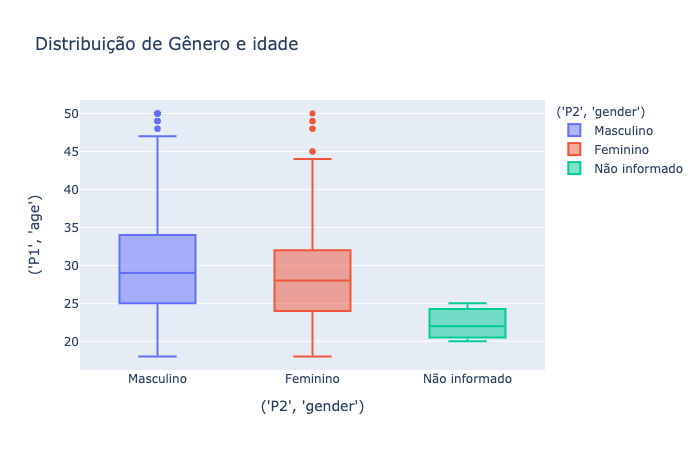
grad_sit = data.groupby(["('P10', 'job_situation')", "('P2', 'gender')"]).size().reset_index()
grad_sit.columns = ["Situação", "Formação", "qtd"]
grad_sit["qtd_p"] = round((grad_sit["qtd"]*100)/grad_sit["qtd"].sum(),2)
fig = px.bar(grad_sit, y="Situação", x="qtd_p", color='Formação', orientation='h', text='qtd_p', title="Vinculo empregatício")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.show()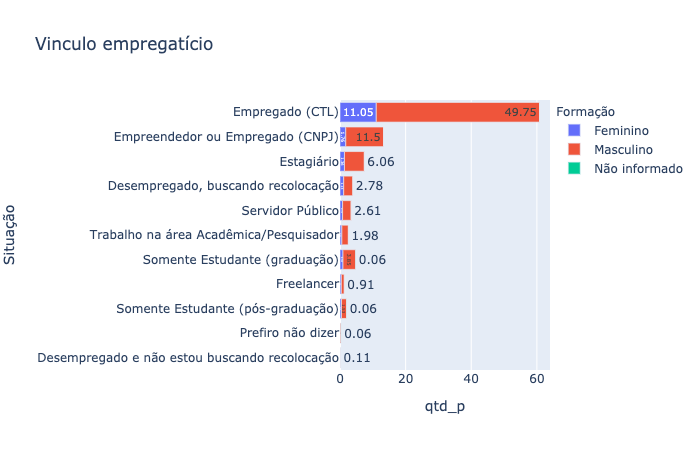
grad_temp = data.groupby(["('P17', 'time_experience_data_science')", "('P2', 'gender')"]).size().reset_index()
grad_temp.columns = ["Tempo de Exepriencia", "Sexo", "qtd"]
grad_temp = grad_temp.replace({"Tempo de Exepriência": {"Não tenho experiência na área de dados": "Sem Experiência"}})
grad_temp["Tempo de Exepriencia"] = grad_temp["Tempo de Exepriencia"].astype("category")
grad_temp.sort_values(by=['qtd'], inplace=True)
fig = px.bar(grad_temp, y="Tempo de Exepriencia", x="qtd", color='Sexo', orientation='h', text='qtd', title="Tempo de experiência na área de Data Science")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.update_layout(yaxis=dict(tickformat=".2%"))
fig.show()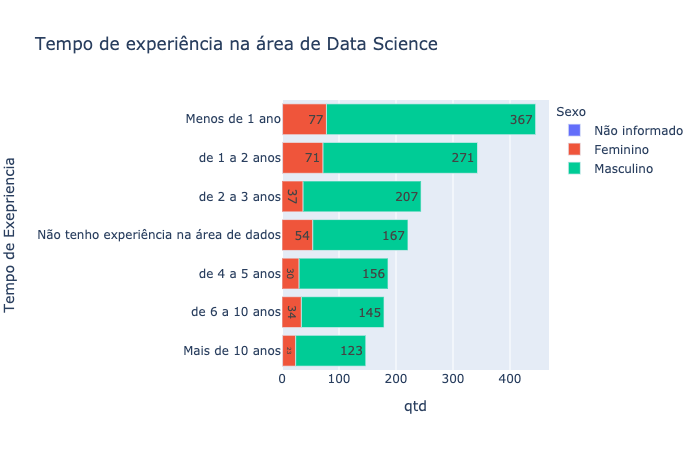
grad_sal = data.groupby(["('P16', 'salary_range')", "('P2', 'gender')"]).size().reset_index()
grad_sal.columns = ["Salario", "Sexo", "qtd"]
grad_sal = grad_sal.replace({ "Salario": {"de R$ 4.001/mês a R$ 6.000/mês": "4~6 R$ mil",
"de R$ 8.001/mês a R$ 12.000/mês": "8~12 R$ mil",
"de R$ 6.001/mês a R$ 8.000/mês": "6~8 R$ mil",
"de R$ 3.001/mês a R$ 4.000/mês": "3~4 R$ mil",
"de R$ 1.001/mês a R$ 2.000/mês": "1~2 R$ mil",
"de R$ 2.001/mês a R$ 3000/mês": "2~3 R$ mil",
"de R$ 12.001/mês a R$ 16.000/mês": "12~16 R$ mil",
"Menos de R$ 1.000/mês": "*~1 R$ mil",
"de R$ 16.001/mês a R$ 20.000/mês": "16~20 R$ mil",
"de R$ 20.001/mês a R$ 25.000/mês": "20~25 R$ mil",
"Acima de R$ 25.001/mês": "25~* R$ mil"}})
fig = px.bar(grad_sal, y="Salario", x="qtd", color='Sexo', orientation='h', text='qtd', title="Diferença salarial entre Gênero")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.show()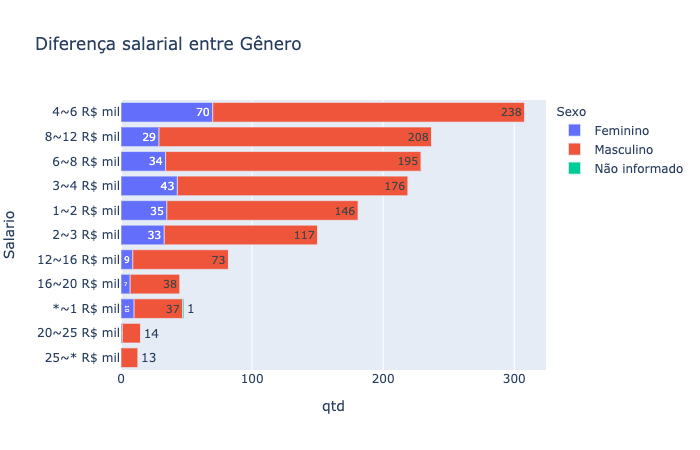
data["('P1', 'age')"] = data["('P1', 'age')"].astype('category').sort_values()
data["('P2', 'gender')"] = data["('P2', 'gender')"].astype('category')
data["('P8', 'degreee_level')"] = data["('P8', 'degreee_level')"].astype('category')
data["('P16', 'salary_range')"] = data["('P16', 'salary_range')"].astype('category')
data["('P6', 'born_or_graduated')"] = data["('P6', 'born_or_graduated')"].astype('category')
data["('P19', 'is_data_science_professional')"] = data["('P19', 'is_data_science_professional')"].astype("object")
data = data.replace({"('P16', 'salary_range')": {"de R$ 4.001/mês a R$ 6.000/mês": "4~6 R$ mil",
"de R$ 8.001/mês a R$ 12.000/mês": "8~12 R$ mil",
"de R$ 6.001/mês a R$ 8.000/mês": "6~8 R$ mil",
"de R$ 3.001/mês a R$ 4.000/mês": "3~4 R$ mil",
"de R$ 1.001/mês a R$ 2.000/mês": "1~2 R$ mil",
"de R$ 2.001/mês a R$ 3000/mês": "2~3 R$ mil",
"de R$ 12.001/mês a R$ 16.000/mês": "12~16 R$ mil",
"Menos de R$ 1.000/mês": "*~1 R$ mil",
"de R$ 16.001/mês a R$ 20.000/mês": "16~20 R$ mil",
"de R$ 20.001/mês a R$ 25.000/mês": "20~25 R$ mil",
"Acima de R$ 25.001/mês": "25~* R$ mil"}})
data_sort = data.sort_values(by="('P16', 'salary_range')", ascending=True)
fig = px.parallel_categories(data_sort,
color="('P19', 'is_data_science_professional')",
dimensions=["('P2', 'gender')",
"('D3', 'anonymized_degree_area')",
"('P8', 'degreee_level')",
"('D6', 'anonymized_role')",
"('P16', 'salary_range')",
"('P19', 'is_data_science_professional')"],
labels={"('P2', 'gender')": "Sexo",
"('P19', 'is_data_science_professional')": "Se considera\n Um DS",
"('P8', 'degreee_level')": "Nível Formação",
"('D3', 'anonymized_degree_area')": "Área Graduação",
"('D6', 'anonymized_role')": "Função",
"('P16', 'salary_range')": "Salário"},
title="Rastreamento dos Perfis dos participantes")
fig.show()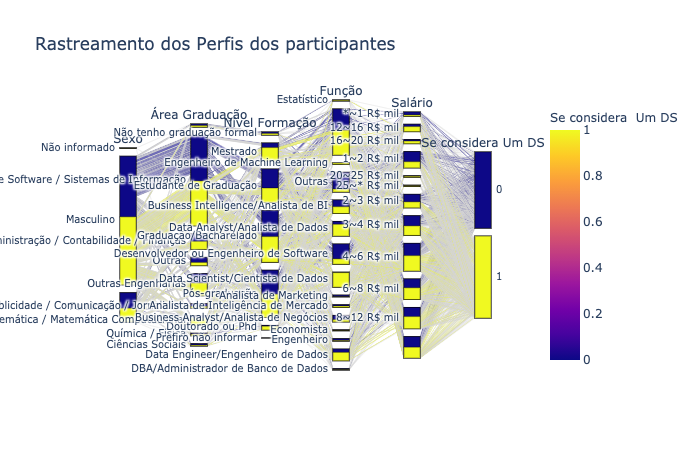
grad_languages = data.groupby(["('P22', 'most_used_proggraming_languages')", "('P2', 'gender')"]).size().reset_index()
grad_languages.columns = ["Linguagem", "Sexo", "qtd"]
grad_languages.sort_values("qtd", inplace=True)
grad_languages = grad_languages.replace({"Linguagem": {"Não utilizo nenhuma das linguagens listadas": "Nenhuma das listada"}})
fig = px.bar(grad_languages, y="Linguagem", x="qtd", color='Sexo', orientation='h', text='qtd', title="Linguagens mais utilizadas")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.show()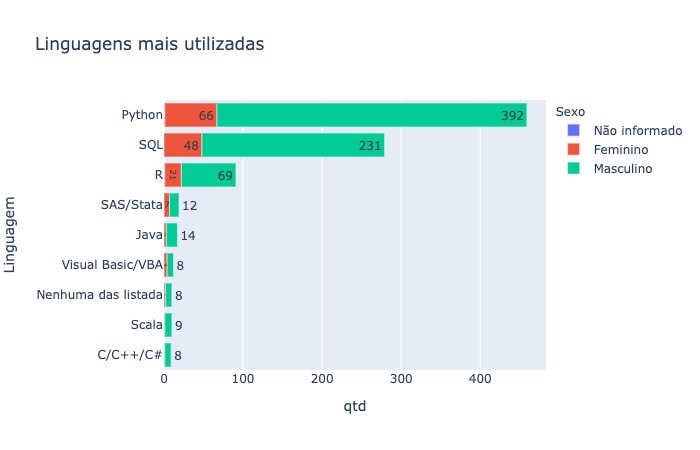
salario = {
"4~6 R$ mil": 5000.,
"8~12 R$ mil": 10000.,
"6~8 R$ mil": 7000.,
"3~4 R$ mil": 3500.,
"1~2 R$ mil": 1500.,
"2~3 R$ mil": 2500.,
"12~16 R$ mil": 14000.,
"*~1 R$ mil": 900.,
"16~20 R$ mil": 18000.,
"20~25 R$ mil": 22500.,
"25~* R$ mil": 26000.
}
data["Salario_Aproximado"] = data["('P16', 'salary_range')"].map(salario)
grad_pl = data.groupby(["('P22', 'most_used_proggraming_languages')", "('P2', 'gender')"])["Salario_Aproximado"].mean().sort_values(ascending=False).reset_index()
grad_pl.columns = ["Linguagens", "Sexo", "Salario"]
grad_pl = grad_pl.replace({"Linguagens": {"Não utilizo nenhuma das linguagens listadas": "Nenhuma das listada"}})
grad_pl["Salario"] = grad_pl["Salario"].round(1)
fig = px.bar(grad_pl, y="Linguagens", x="Salario", color='Sexo', orientation='h', text="Salario", title="Linguagens com maior média salarial x Sexo")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.show()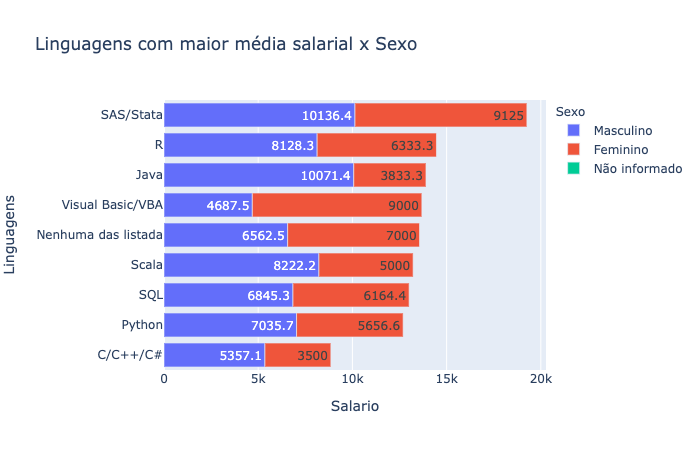
grad_role = data.groupby(["('D6', 'anonymized_role')", "('P2', 'gender')"])['Salario_Aproximado'].mean().sort_values().reset_index()
grad_role.columns = ["Função/Cargo", "Sexo", "Salario"]
grad_role["Salario"] = grad_role["Salario"].round(2)
# grad_role
fig = px.bar(grad_role, y="Função/Cargo", x="Salario", color='Sexo', orientation='h', text="Salario", title="Média salarial aproximada por Função/Cargo")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.show()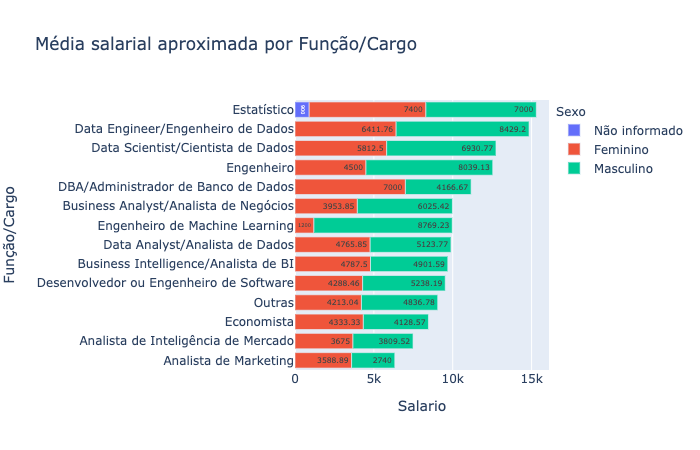
Conclusão!
-
• Entre o comparativo do mercado brasileiro e estrangeiro a uma certa similaridade entre os dois cenários.
-
• O Mercado no Brasil é predominantemente masculino e com uma maior frequência de salário entre 4~6 mil reais, bem diferente do que é anunciado na mídia.
-
• Boa parte dos profissionais mantém vínculo empregatício regido pela CLT. As linguagens mais utilizadas são Python, SQL e R, ótimas linguagens na minha opnião, pois têm recursos vastos e uma curva de aprendizagem bem pequena.
-
• Os maiores salários estão com profissionais que utilizam linguagens como SAS/Stat, R e Java. Isto provavelmente é devido a grandes empresas que desenvolveram suas áreas de dados sem ter quer precisar implementar uma nova linguagem ou arquitetura.
Obrigado por ler! Algum comentário ou feedback? Me mande uma mensagem na página de contato. Você pode me encontrar no LinkedIn.
Esse projeto foi baseado em um exemplo da documentação da DGL GitHub.